News
► [NEW!] [Feb 2026] 1 paper accepted by EG2026.
► [NEW!] [Oct. 2025] 3 papers accepted by ICCV 2025.
► [NEW!] [July 2025] 1 paper accepted by SIGGRAPH 2025.
► [Feb 2025] 4 papers accepted by CVPR 2025. 1 paper accepted by CVPR 2025 CVEU workshop.
► [Feb 2025] Promoted to Senior Research Scientist at Adobe Research!
► [Oct. 2024] 2 papers accepted by NeurIPS 2024.
► [July 2024] 2 papers accepted by ECCV 2024.
► [Jan. 2024] 1 papers accepted by 3DV 2024.
See more earlier updates...
Publications
Video Generation and Visual Effects
 |
WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Jisu Nam, Yicong Hong, Chun-Hao Paul Huang, Feng Liu, JoungBin Lee, Jiyoung Kim, Siyoon Jin, Yunsung Lee, Jaeyoon Jung, Suhwan Choi, Seungryong Kim, Yang Zhou Arxiv 2026 PDF Project |
 |
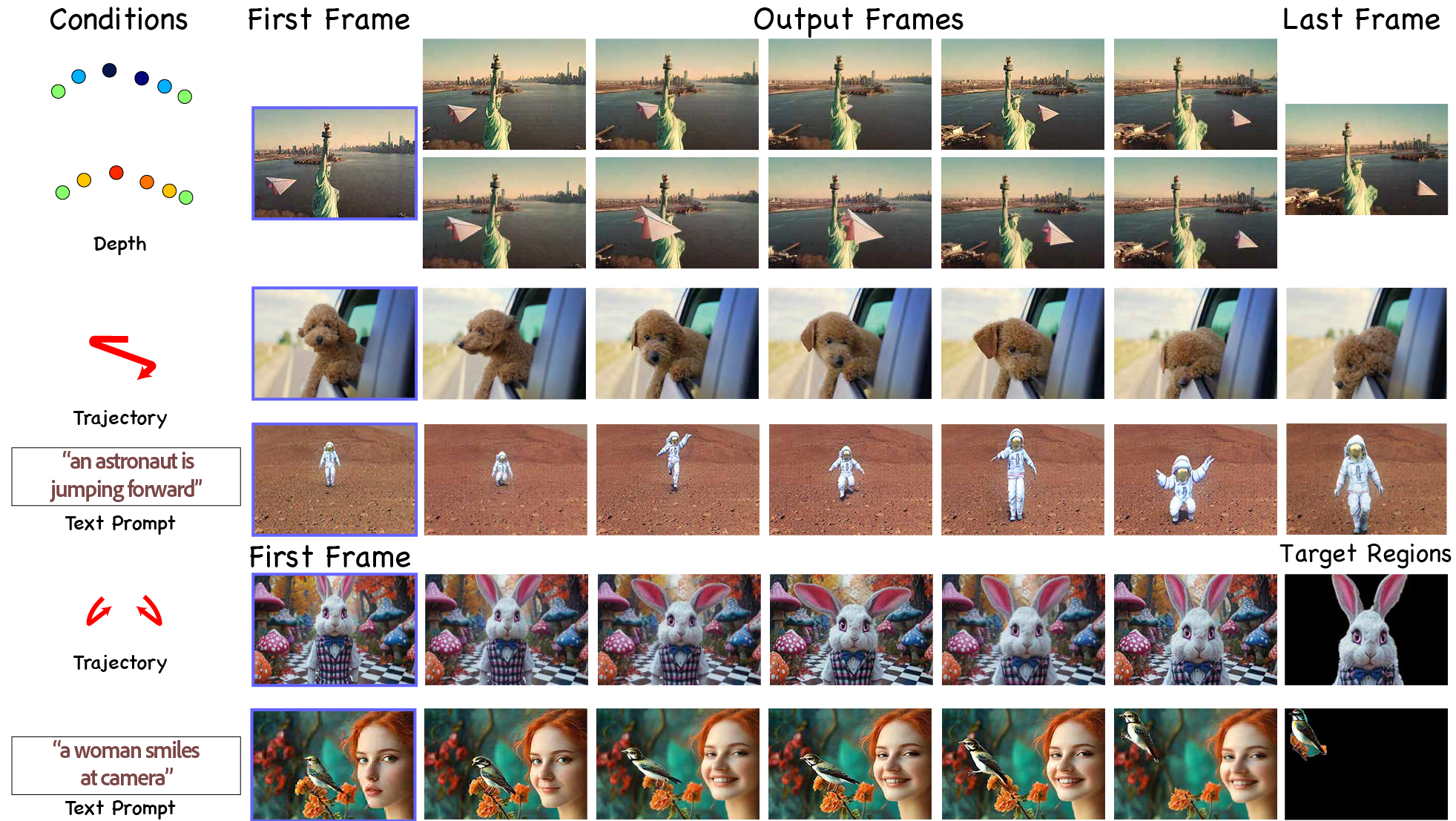
RELIC: Interactive Video World Model with Long-Horizon Memory
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, Kalyan Sunkavalli, Feng Liu, Zhengqi Li, Hao Tan Arxiv 2025 PDF Project |
 |
MultiCOIN: Multi-Modal COntrollable Video INbetweening
Maham Tanveer, Yang Zhou, Simon Niklaus, Ali Mahdavi Amiri, Hao Zhang, Krishna Kumar Singh, Nanxuan Zhao EG2026 PDF Project |
 |
VEGGIE: Instructional Editing and Reasoning Video Concepts with Grounded Generation
Shoubin Yu, Difan Liu, Ziqiao Ma, Yicong Hong, Yang Zhou, Hao Tan, Joyce Chai, Mohit Bansal ICCV 2025 PDF Project |
 |
VideoGigaGAN: Towards Detail-rich Video Super-Resolution
Yiran Xu, Taesung Park, Richard Zhang, Yang Zhou, Eli Shechtman, Feng Liu, Jia-Bin Huang, Difan Liu CVPR 2025 PDF Project |
 |
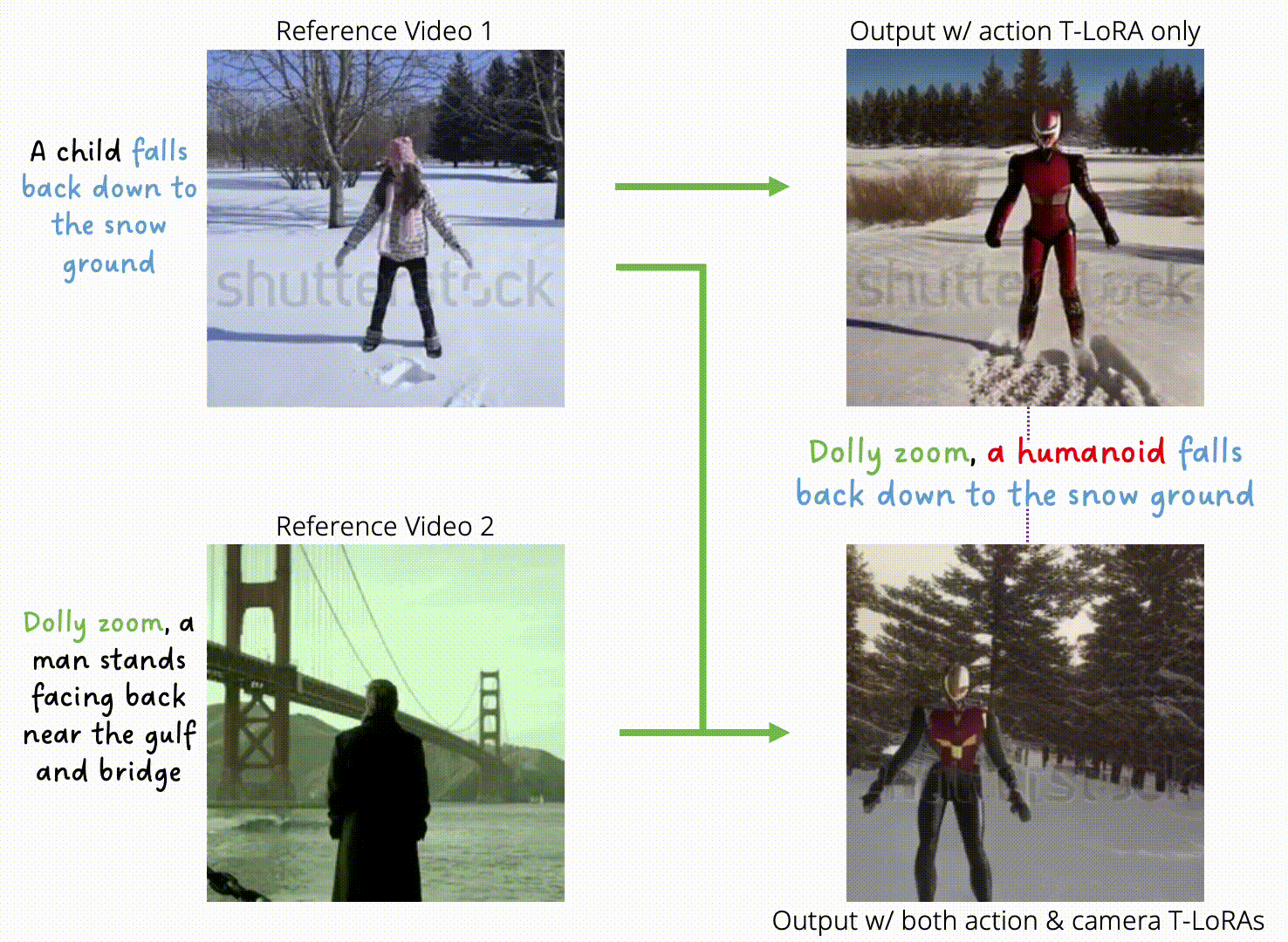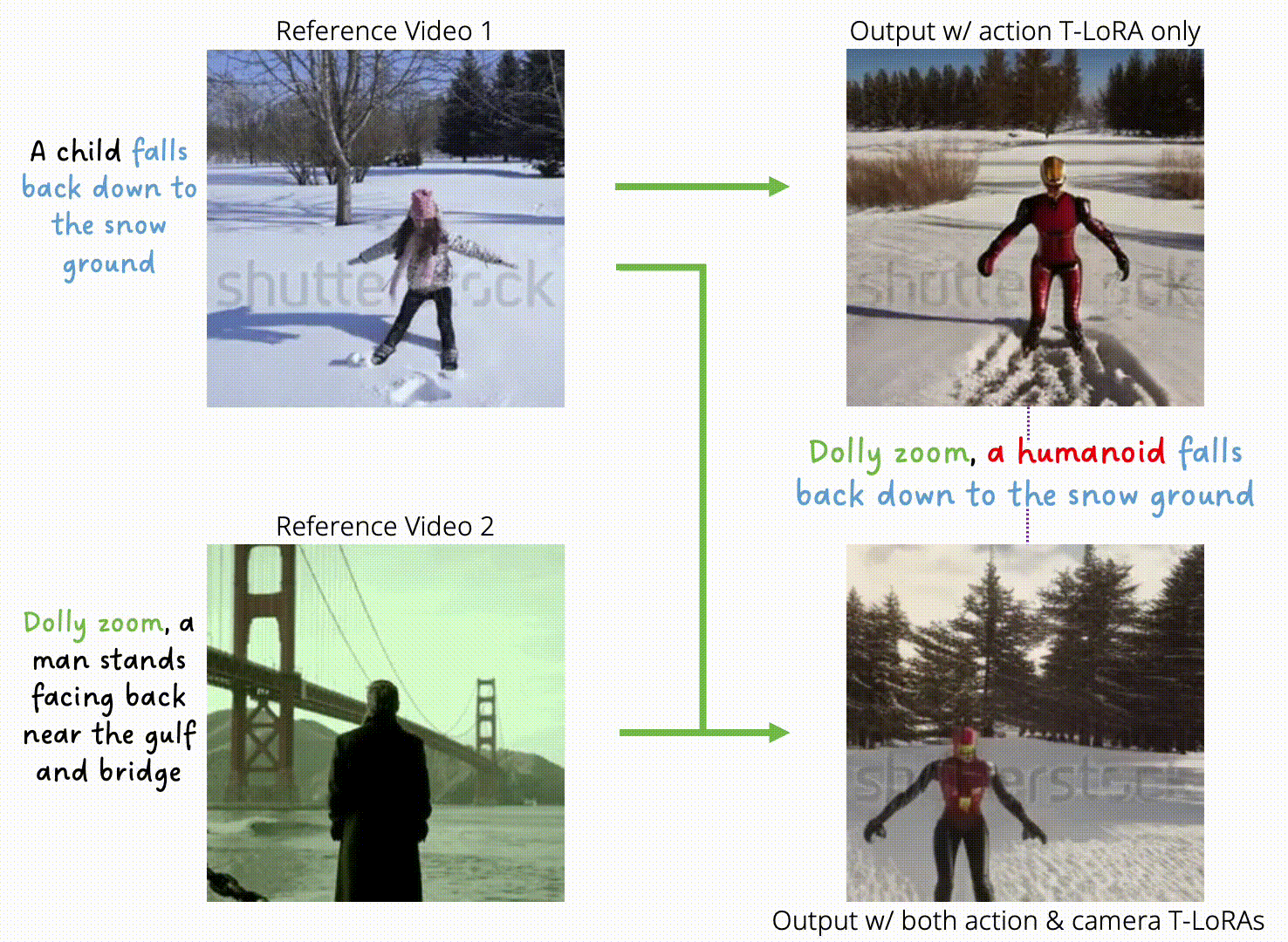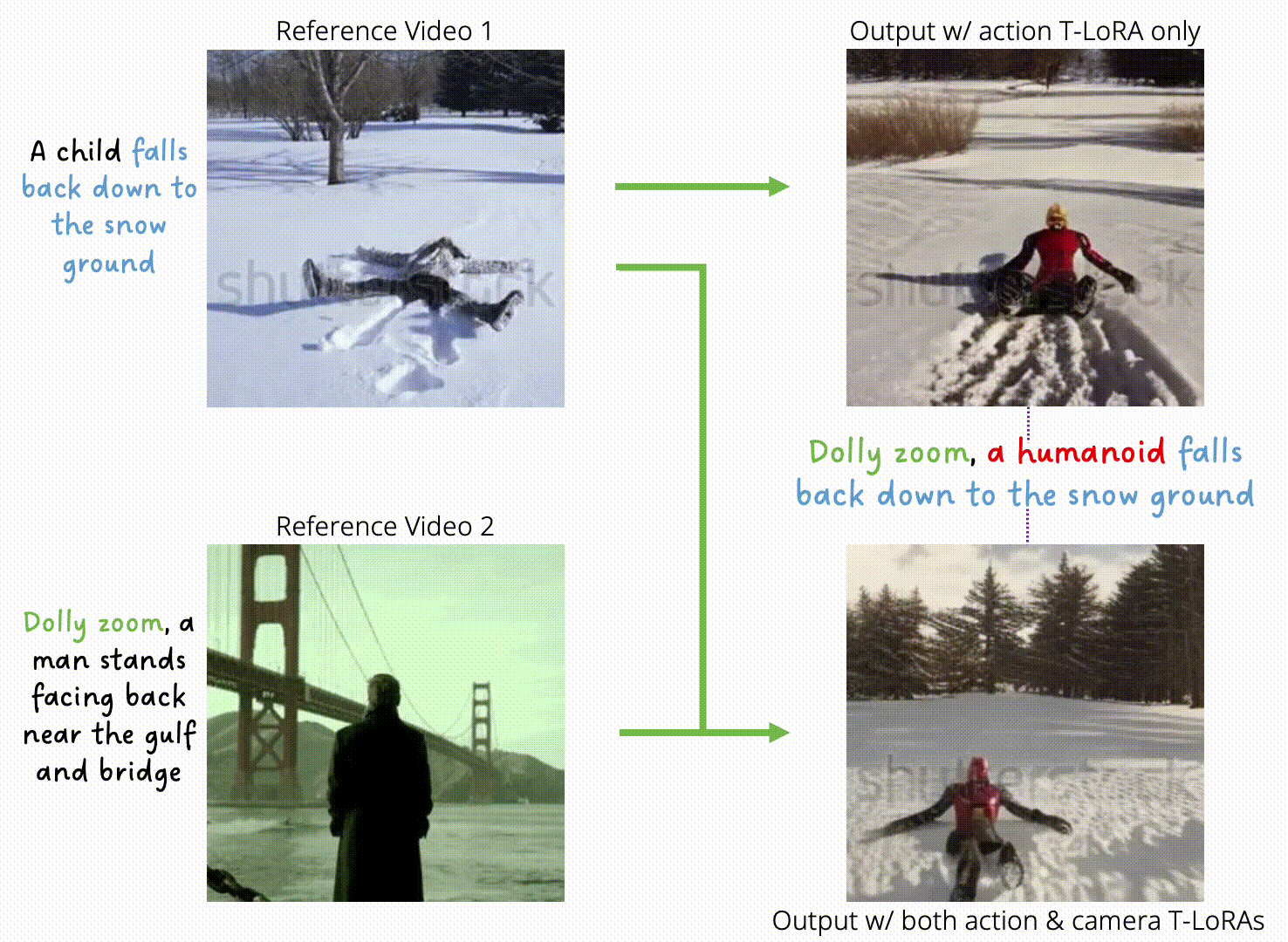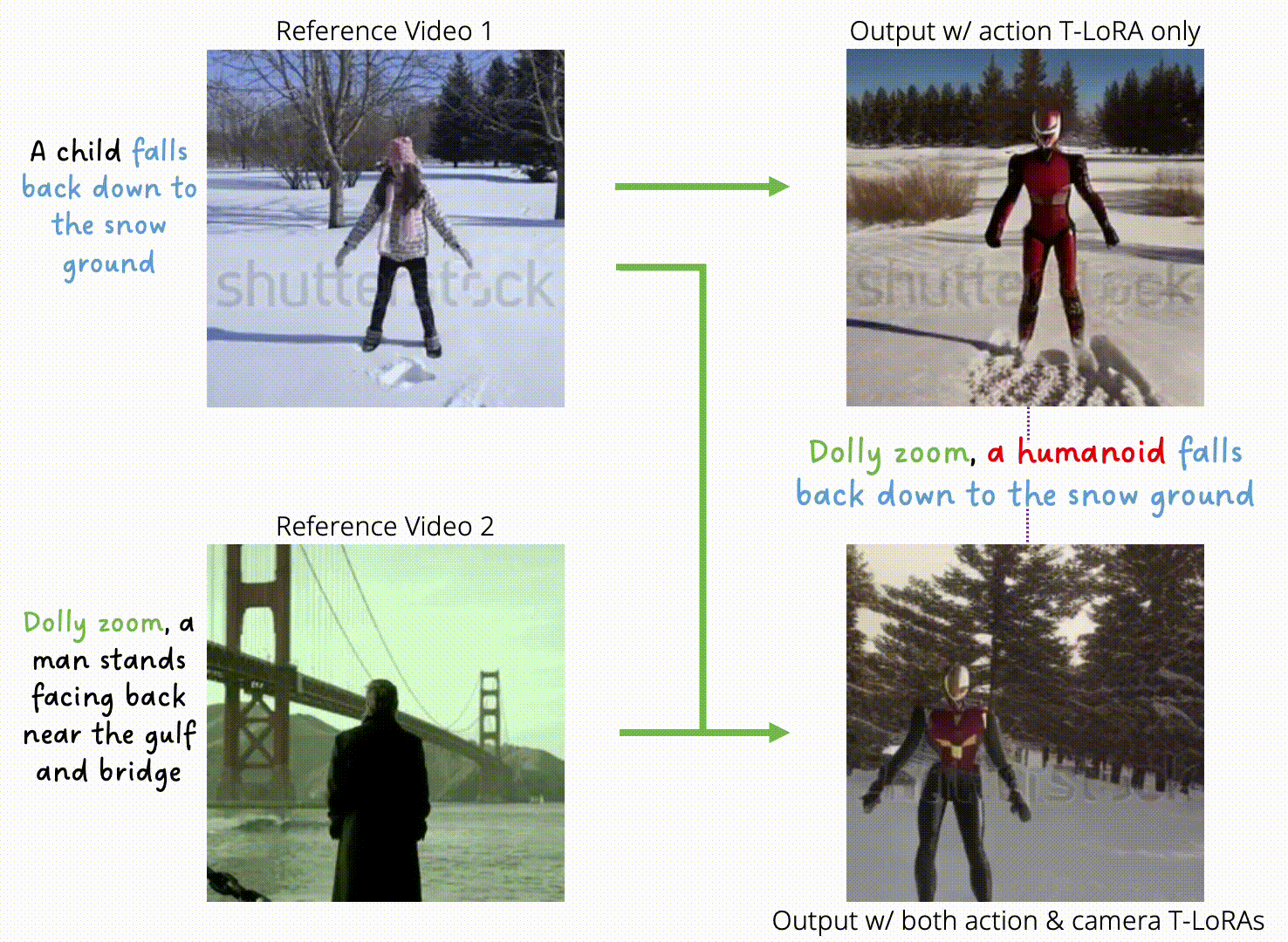
Progressive Autoregressive Video Diffusion Models
Desai Xie, Zhan Xu, Yicong Hong, Hao Tan, Difan Liu, Feng Liu, Arie Kaufman, Yang Zhou CVPR 2025 CVEU Workshop PDF Project |
 |
Customize-a-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Ren, Yixuan, Yang Zhou, Jimei Yang, Jing Shi, Difan Liu, Feng Liu, Mingi Kwon, and Abhinav Shrivastava ECCV 2024 PDF Project |
 |
HARIVO: Harnessing Text-to-Image Models for Video Generation
Mingi Kwon, Seoung Wug Oh, Yang Zhou, Joon-Young Lee, Difan Liu, Haoran Cai, Baqiao Liu, Feng Liu, Youngjung Uh ECCV 2024 PDF Project |
 |
Jump Cut Smoothing for Talking Heads
Wang, Xiaojuan, Taesung Park, Yang Zhou, Eli Shechtman, and Richard Zhang Arxiv 2024 PDF Project |
 |
ActAnywhere: Subject-Aware Video Background Generation
Pan, Boxiao, Zhan Xu, Chun-Hao Paul Huang, Krishna Kumar Singh, Yang Zhou, Leonidas J. Guibas, and Jimei Yang NeurIPS 2024 PDF Project |
Digital Human and Characters
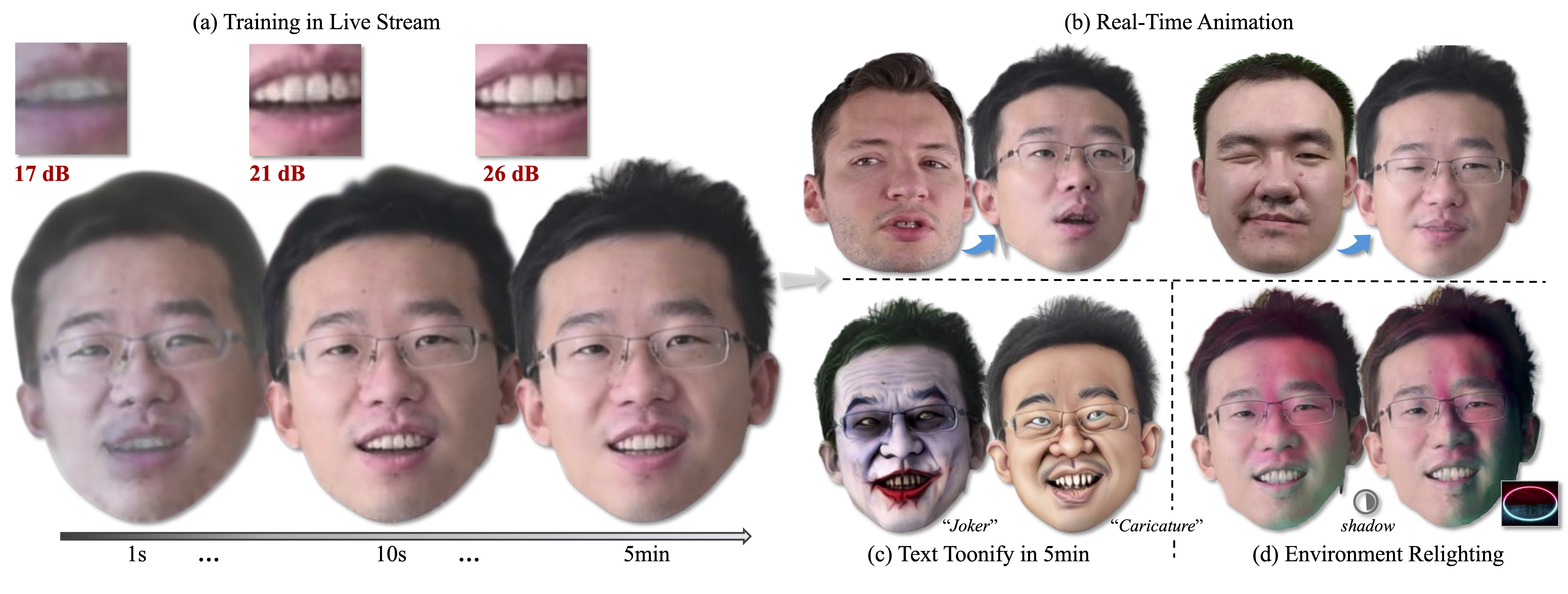 |
StreamME: Simplify 3D Gaussian Avatar within Live Stream
Luchuan Song, Yang Zhou, Zhan Xu, Yi Zhou, Deepali Aneja, Chenliang Xu SIGGRAPH 2025 PDF Project |
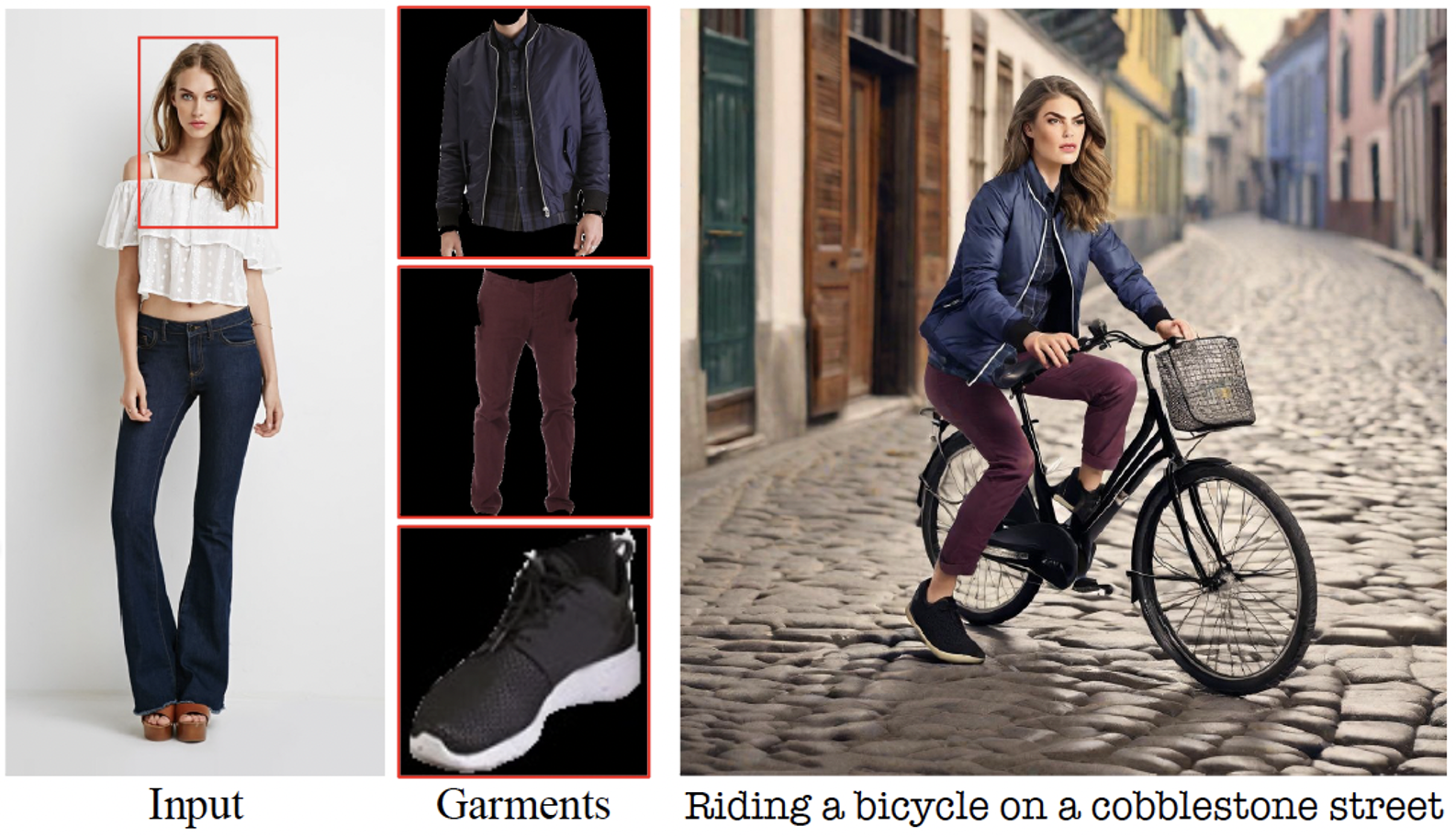 |
Visual Persona: Foundation Model for Full-Body Human Customization
Jisu Nam, Soowon Son, Zhan Xu, Jing Shi, Difan Liu, Feng Liu, Seungryong Kim, Yang Zhou CVPR 2025 PDF Project |
 |
Free-viewpoint Human Animation with Pose-correlated Reference Selection
Fa-Ting Hong, Zhan Xu, Haiyang Liu, Qinjie Lin, Luchuan Song, Zhixin Shu, Yang Zhou, Duygu Ceylan, Dan Xu CVPR 2025 |
 |
Move-in-2D: 2D-Conditioned Human Motion Generation
Hsin-Ping Huang, Yang Zhou, Jui-Hsien Wang, Difan Liu, Feng Liu, Ming-Hsuan Yang, Zhan Xu CVPR 2025 PDF Project |
 |
Video Motion Graphs
Haiyang Liu, Zhan Xu, Fa-Ting Hong, Hsin-Ping Huang, Yi Zhou, Yang Zhou ICCV 2025 PDF Project |
 |
Template-Free Single-View 3D Human Digitalization with Diffusion-Guided LRM
Weng, Zhenzhen, Jingyuan Liu, Hao Tan, Zhan Xu, Yang Zhou, Serena Yeung-Levy, and Jimei Yang Arxiv 2024 PDF Project |
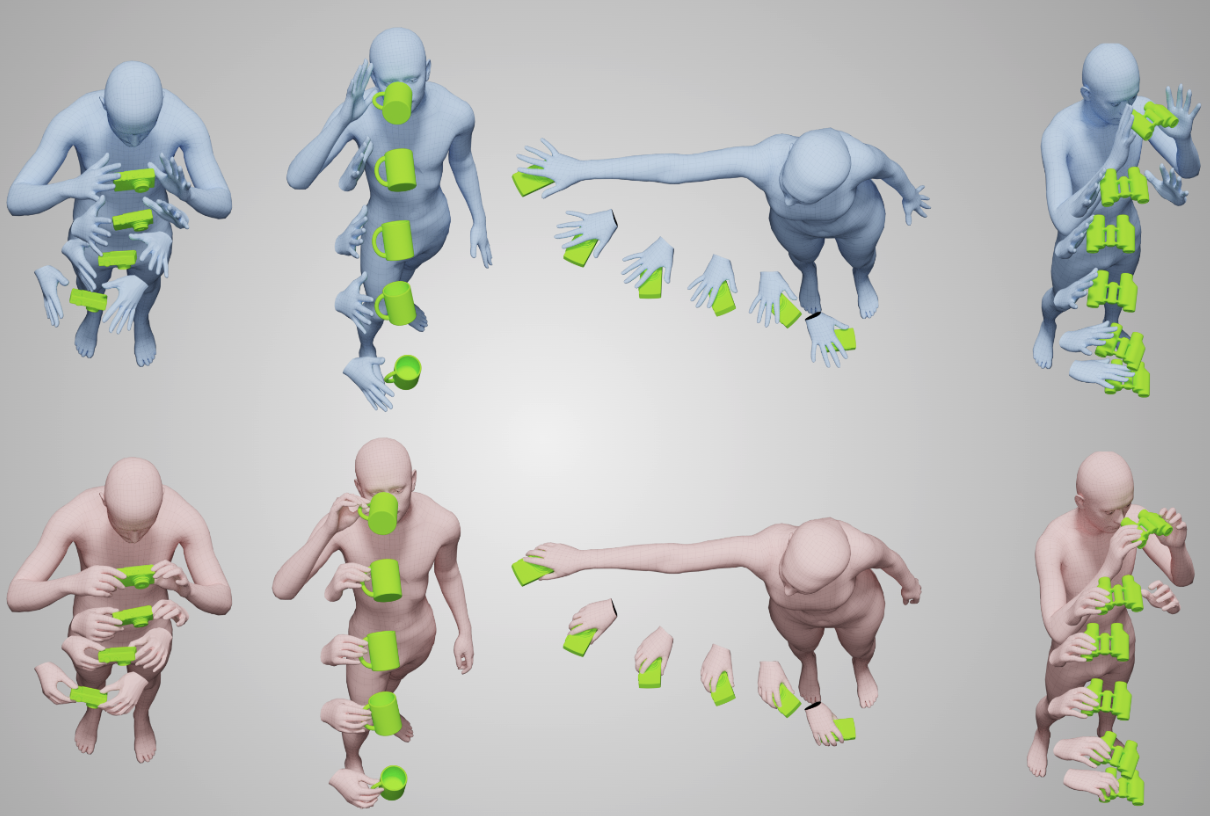 |
GRIP: Generating Interaction Poses Using Spatial Cues and Latent Consistency
Taheri, Omid, Yi Zhou, Dimitrios Tzionas, Yang Zhou, Duygu Ceylan, Soren Pirk, and Michael J. Black. 3DV 2024 PDF Project |
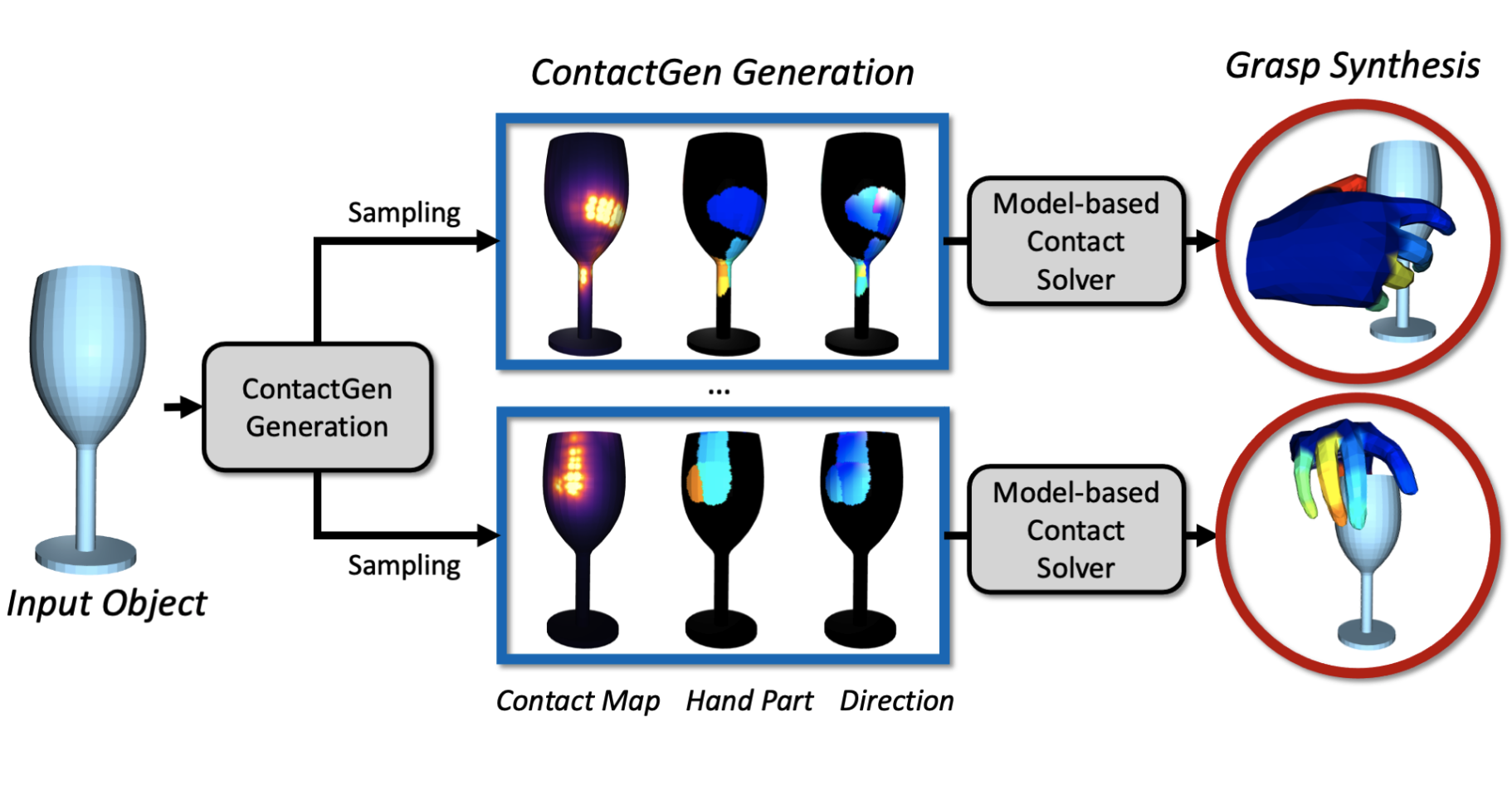 |
ContactGen: Generative Contact Modeling for Grasp Generation
Liu, Shaowei, Yang Zhou, Jimei Yang, Saurabh Gupta, and Shenlong Wang ICCV 2023 PDF Project |
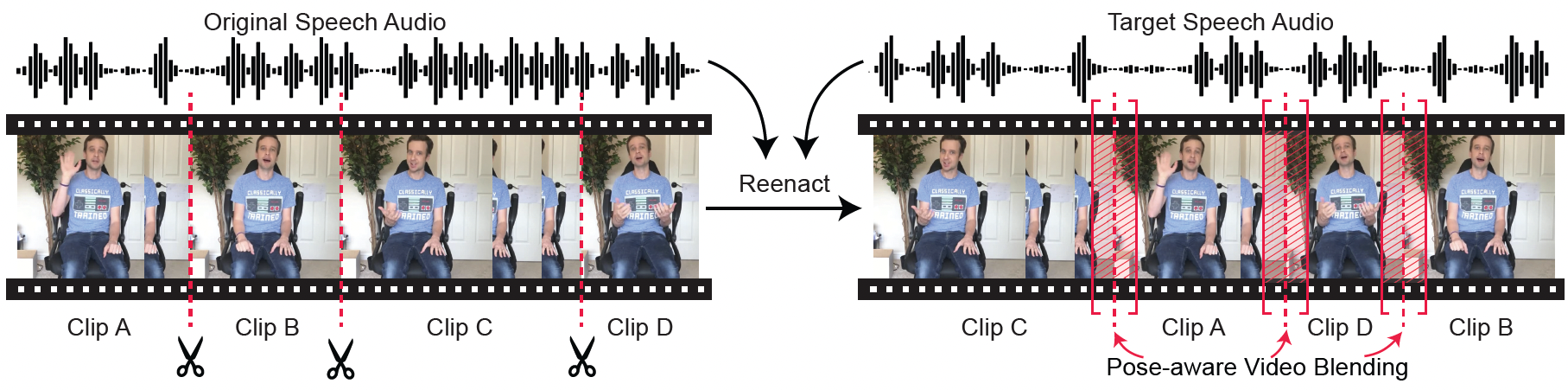 |
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Yang Zhou, Jimei Yang, Dingzeyu Li, Jun Saito, Deepali Aneja, and Evangelos Kalogerakis CVPR 2022 PDF Project |
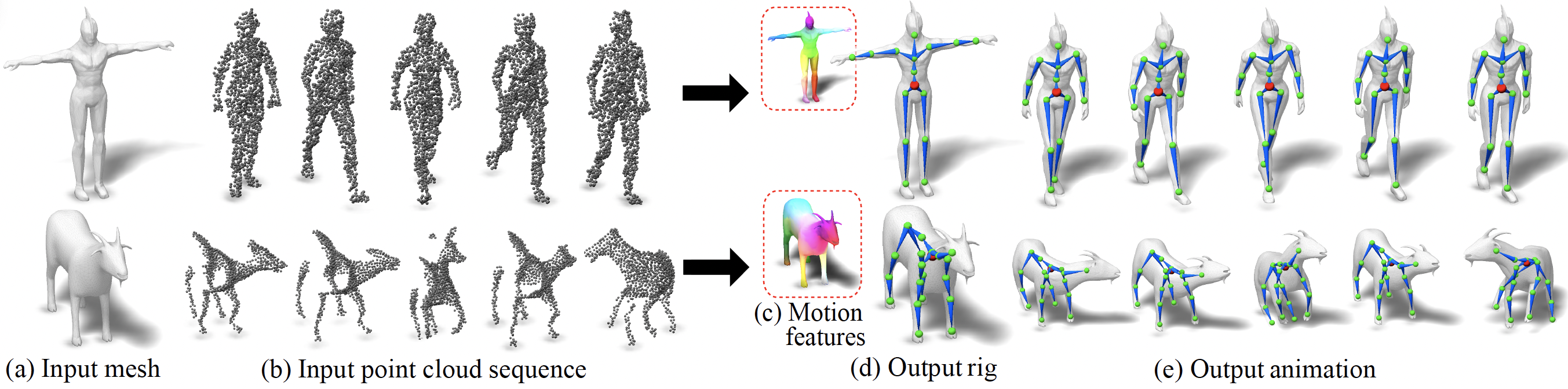 |
MoRig: Motion-Aware Rigging of Character Meshes from Point Clouds
Zhan Xu, Yang Zhou, Li Yi, and Evangelos Kalogerakis SIGGRAPH ASIA 2022 PDF Project |
|
|
Skeleton-free Pose Transfer for Stylized 3D Characters
Zhouyingcheng Liao, Jimei Yang, Jun Saito, Gerard Pons-Moll, and Yang Zhou ECCV 2022 PDF Project |
 |
Learning Visibility for Robust Dense Human Body Estimation
Chun-Han Yao, Jimei Yang, Duygu Ceylan, Yi Zhou, Yang Zhou, and Ming-Hsuan Yang ECCV 2022 PDF Project |
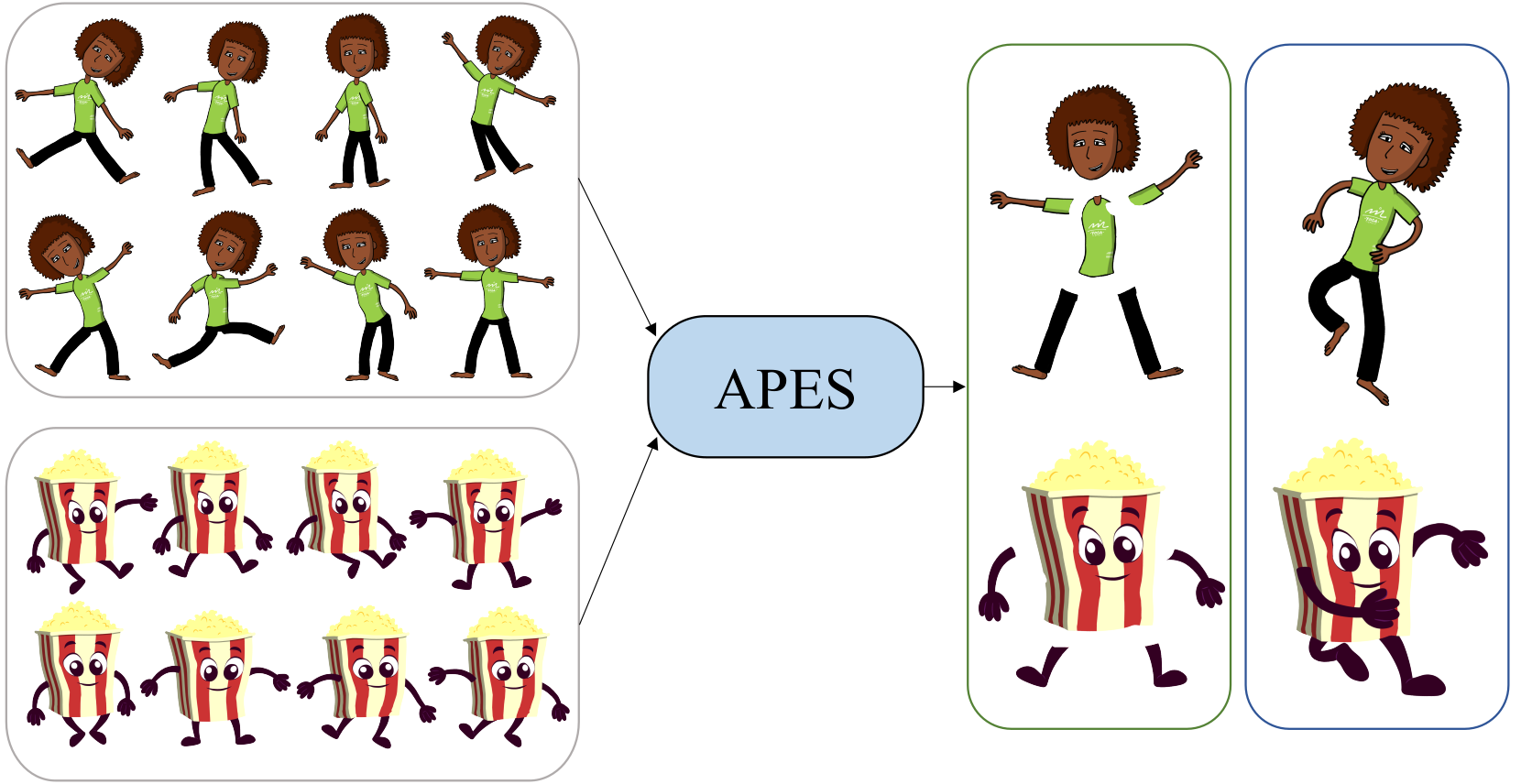 |
APES: Articulated Part Extraction from Sprite Sheets
Zhan Xu, Matthew Fisher, Yang Zhou, Deepali Aneja, Rushikesh Dudhat, Li Yi, and Evangelos Kalogerakis CVPR 2022 PDF Project |
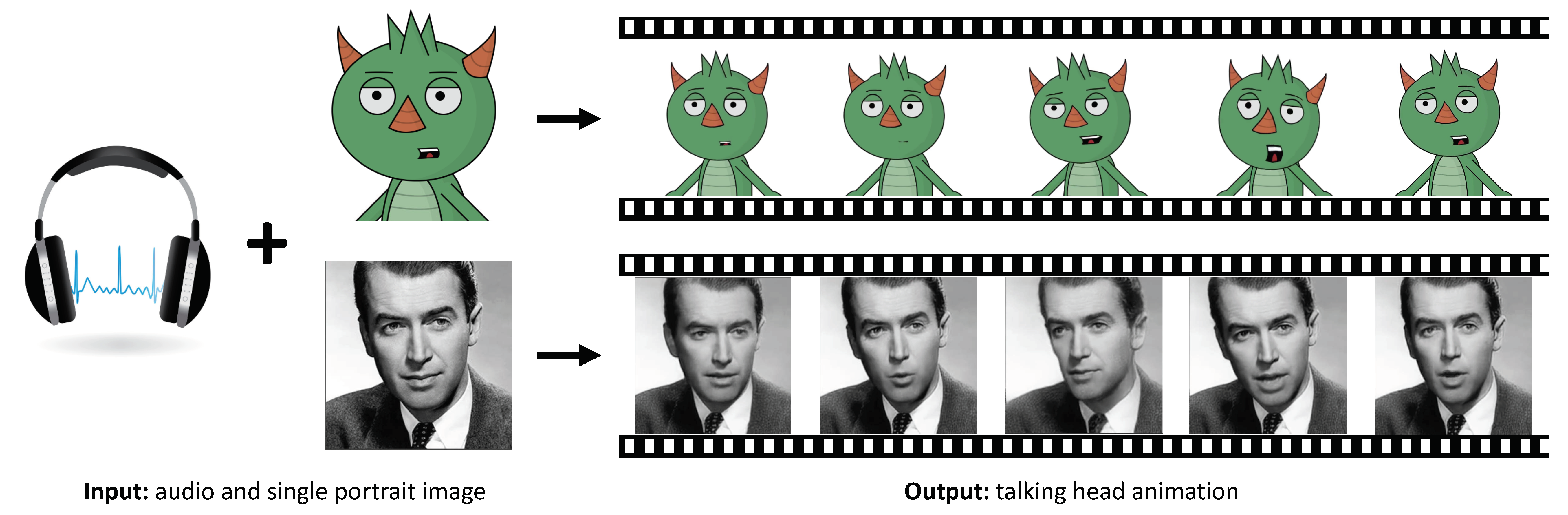 |
MakeItTalk: Speaker-Aware Talking-Head Animation
Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li SIGGRAPH ASIA 2020 PDF Project Video 1 Video 2 |
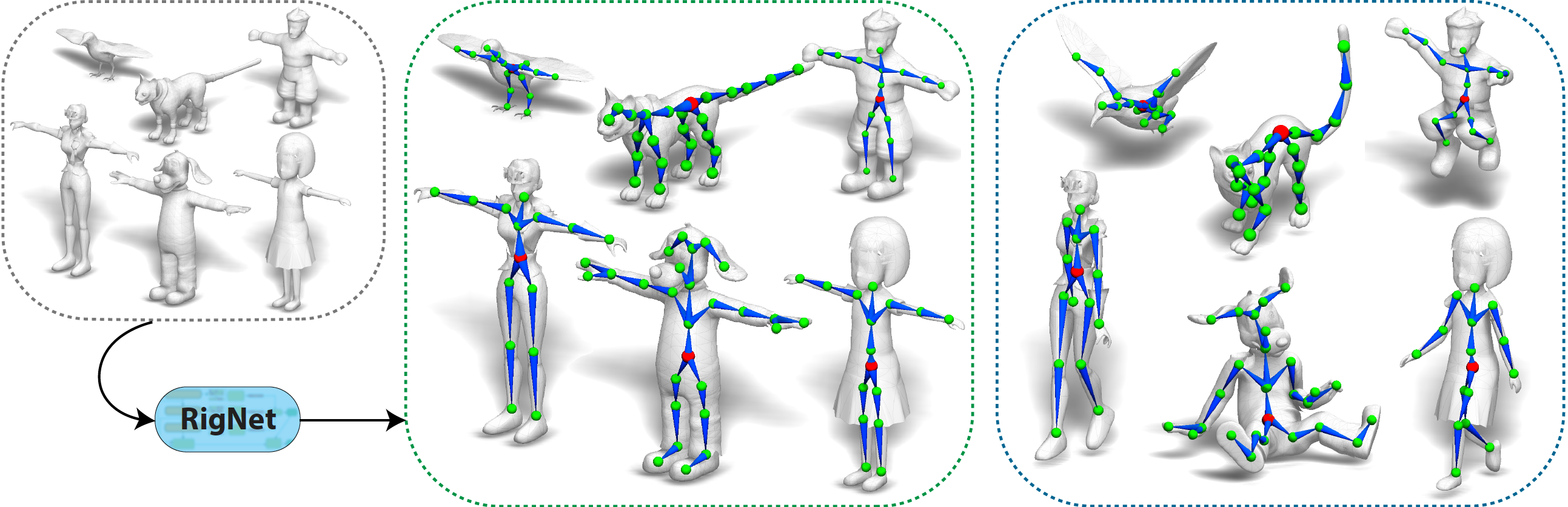 |
RigNet: Neural Rigging for Articulated Characters
Zhan Xu, Yang Zhou, Evangelos Kalogerakis, Chris Landreth, and Karan Singh SIGGRAPH 2020 PDF Project |
 |
Predicting Animation Skeletons for 3D Articulated Models via Volumetric Nets
Zhan Xu, Yang Zhou, Evangelos Kalogerakis, and Karan Singh. 3DB 2019 PDF Project |
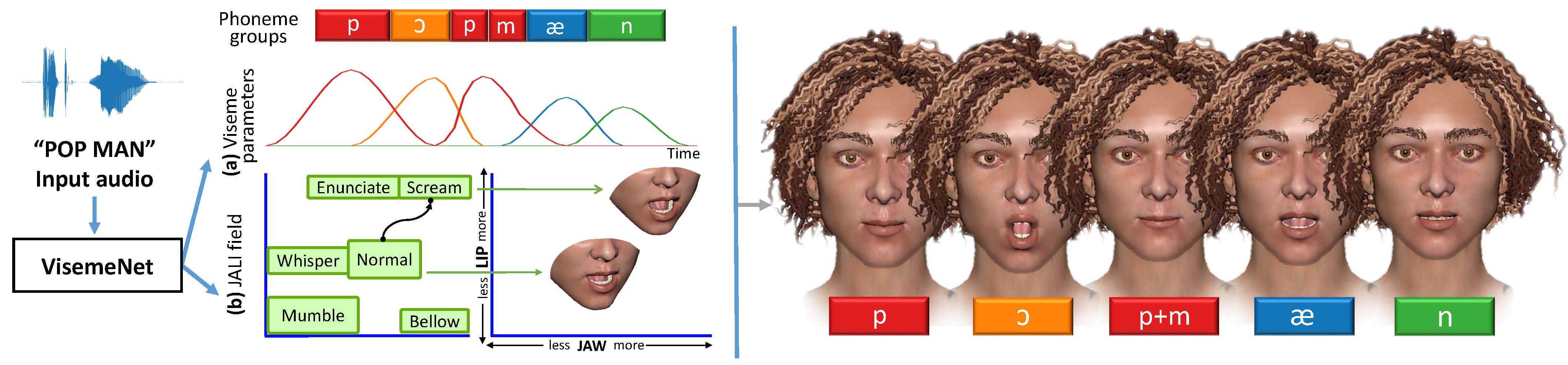 |
VisemeNet: Audio-Driven Animator-Centric Speech Animation
Yang Zhou, Zhan Xu, Chris Landreth, Subhransu Maji, Evangelos Kalogerakis, and Karan Singh SIGGRAPH 2018 PDF Project |
3D Object and Scene Synthesis
 |
DMesh++: An Efficient Differentiable Mesh for Complex Shapes
Sanghyun Son, Matheus Gadelha, Yang Zhou, Matthew Fisher, Zexiang Xu, Yi-Ling Qiao, Ming C. Lin, Yi Zhou ICCV 2025 PDF Project |
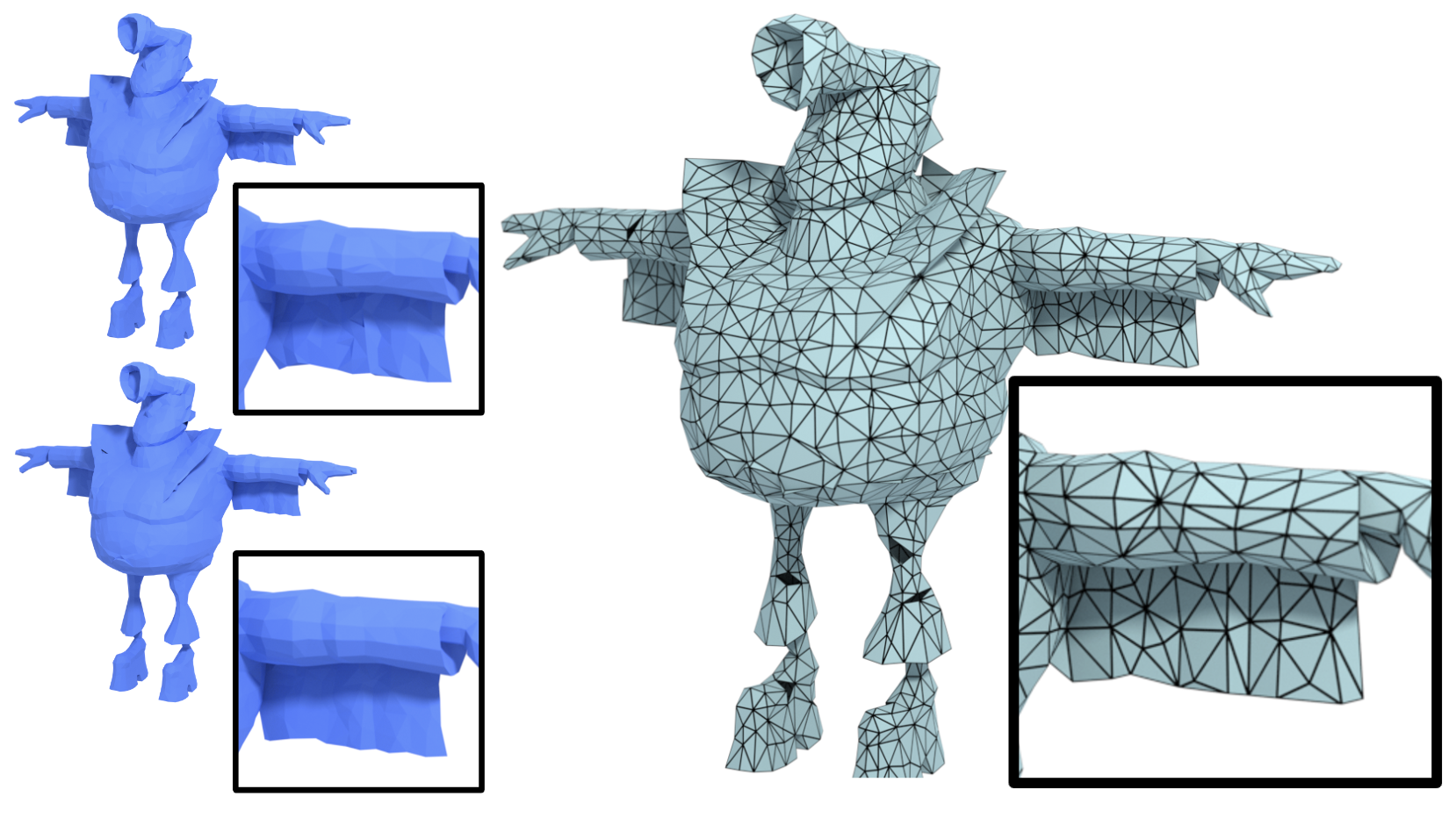 |
DMesh: A Differentiable Mesh Representation
Sanghyun Son, Matheus Gadelha, Yang Zhou, Zexiang Xu, Ming Lin, Yi Zhou NeurIPS 2024 PDF Project |
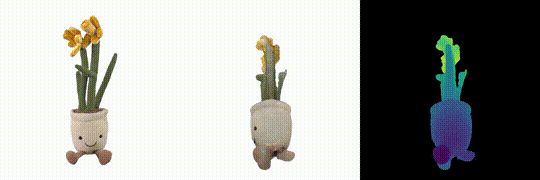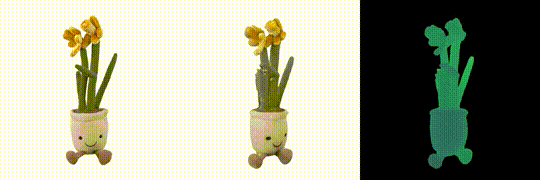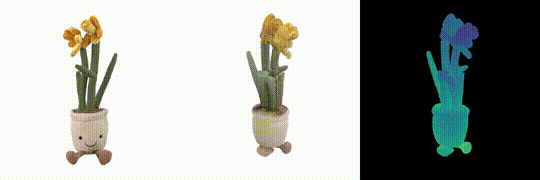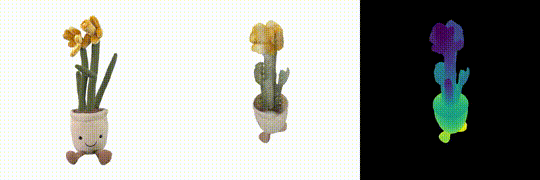 |
LRM: Large Reconstruction Model for Single Image to 3D
Hong, Yicong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan ICLR 2024 PDF Project |
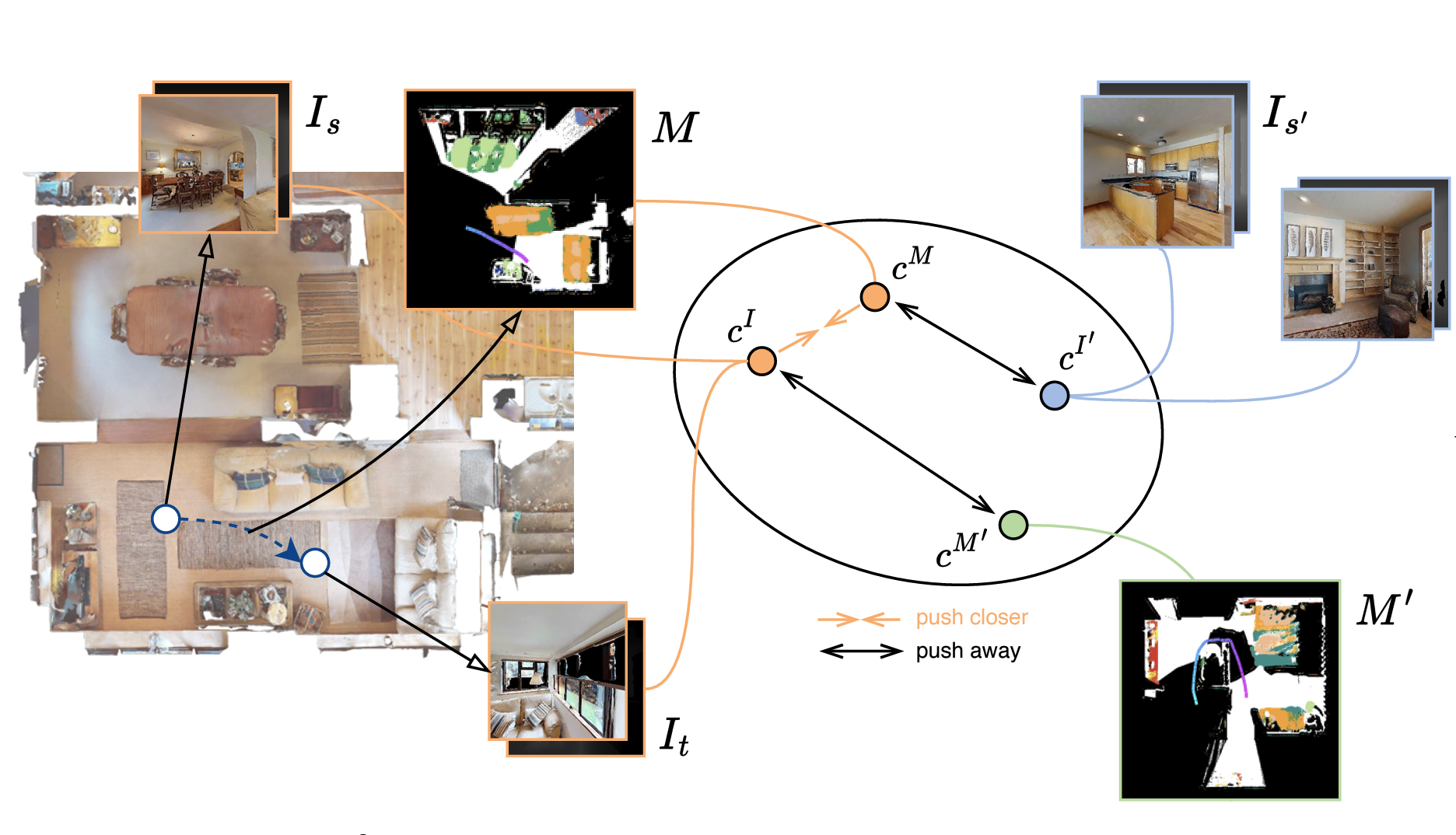 |
Learning Navigational Visual Representations with Semantic Map Supervision
Hong, Yicong, Yang Zhou, Ruiyi Zhang, Franck Dernoncourt, Trung Bui, Stephen Gould, and Hao Tan ICCV 2023 |
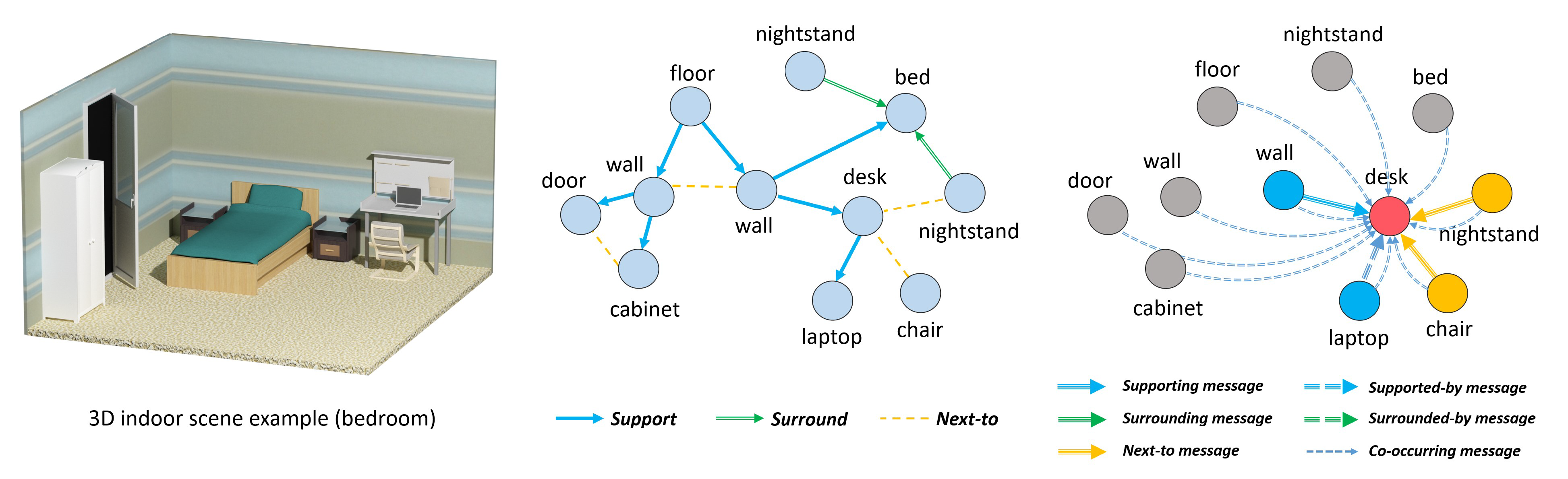 |
SceneGraphNet: Neural Message Passing for 3D Indoor Scene Augmentation
Yang Zhou, Zachary While, and Evangelos Kalogerakis ICCV 2019 PDF Project |
Experience

Adobe, Inc | Media Intelligent Lab
May 2021 | Research ScientistWorking on various research projects including video generation, digital human, 3D generation, etc.
Adobe, Inc | Media Intelligent Lab
June, 2020 | InternCollaborate with researchers on 3D facial/skeleton animations based on deep learning approaches.
Our intern project #OnTheBeatSneak was presented at Adobe MAX 2020 (Sneak Peek).
Adobe, Inc | Creative Intelligence Lab
June, 2019 | InternCollaborate with researchers on audio-driven cartoon and real human facial animations and lip-sync technologies based on deep learning approaches.
Our intern project #SweetTalk was presented at Adobe MAX 2019 (Sneak Peek).

Wayfair, Inc | Wayfair Next Research
June, 2018 | Research InternWorking on 3D scene systhesis based on deep learning approaches.

NetEase Game, Inc
June, 2015 | Management TraineeWorking on mobile game design, especially on profit models and user-experiences.
Contact Me
Best way to reach me is to send an Email